How Often Has GitHub Gone Down? A Data-Backed Look at 2024 Outages

GitHub, a platform offering version control and collaboration services for software development, plays a pivotal role in managing code, tracking issues and pull requests, and deploying software. As millions of developers and businesses rely on GitHub's infrastructure, its reliability is crucial.
Tracking GitHub's outages and understanding their frequency is essential, particularly for organizations that depend on the platform for critical processes. This article delves into the frequency of downtime and degraded performance in GitHub's ecosystem in 2024, while also providing strategies for minimizing the impact of potential service disruptions.
What is an Outage?
An outage refers to any disruption in GitHub's services, either partial or full. Major outages involve complete service disruption, where users can't access core features like project files or repositories. Minor outages typically involve partial service degradation, such as delays in API request processing or limited access to services like GitHub Codespaces. Understanding these distinctions helps clarify the severity and potential impact of each incident.
How Often Has GitHub Gone Down?
In 2024, GitHub experienced 119 incidents, ranging from short-lived service degradations to more significant outages. These incidents primarily affected key components like GitHub Actions, API Requests, and Git Operations.
This data is based on IsDown's 2024 historical monitoring records for GitHub, which track official status updates and user-reported incidents across the platform.
Breakdown by Severity
- Major outages: 26 incidents
- Minor outages: 93 incidents
Although the majority of disruptions were minor, the volume of outages is still significant—particularly for teams that depend on CI/CD tools and code repositories.
Average Downtime
On average, GitHub incidents in 2024 lasted approximately 106.4 minutes (about 1 hour and 46 minutes). This figure accounts for both minor delays and major service interruptions, providing a general benchmark of GitHub's recovery time.
Minor outages, which made up roughly 75% of all incidents, often caused slowdowns in services like the API, Webhooks, and Codespaces. Major ones, though less frequent, resulted in degraded performance across GitHub services, leading to full disruption for 1 to 6 hours and affecting critical features such as codebase access and CI/CD workflows.
GitHub Outage Trends
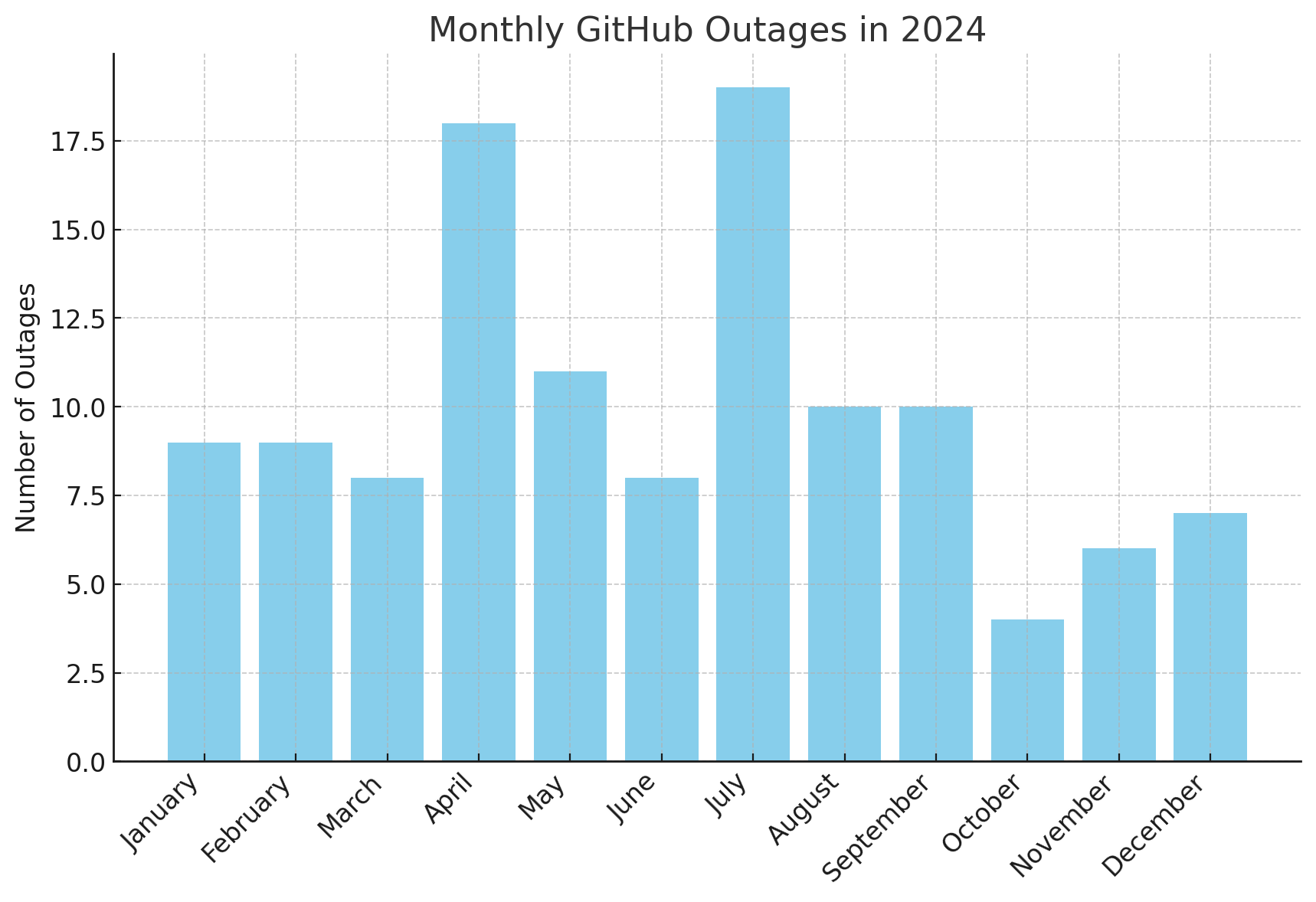
Some months stood out for having more frequent incidents, suggesting potential seasonal spikes in service instability. Here's the complete monthly breakdown:
- January: 9 incidents
- February: 9 incidents
- March: 8 incidents
- April: 18 incidents
- May: 11 incidents
- June: 8 incidents
- July: 19 incidents
- August: 10 incidents
- September: 10 incidents
- October: 4 incidents
- November: 6 incidents
- December: 7 incidents
The heaviest activity occurred in July and April, indicating mid-year instability. In contrast, October had the fewest recorded outages, possibly pointing to a more stable operational period during that month.
Longest and Shortest Incidents
- Longest outage: A Copilot-related incident that lasted 1,149 minutes (over 19 hours)
- Shortest outage: A Git Operations issue that was resolved in just 6 minutes
These two examples illustrate the range of severity and GitHub's ability to recover quickly in some cases, while longer disruptions still occasionally occur—especially with newer or highly integrated features.
Most Frequently Affected GitHub Components

While GitHub supports a wide array of services, certain components were disproportionately affected by outages throughout 2024. Below are the top 10 most frequently impacted:
- GitHub Actions – 25 incidents
- Issues – 16 incidents
- Codespaces – 14 incidents
- Git Operations – 13 incidents
- Pull Requests – 10 incidents
- Packages – 10 incidents
- Webhooks – 9 incidents
- Website – 8 incidents
- API Requests – 7 incidents
- Copilot – 6 incidents
Other components—such as Projects, Notifications, Pages, and Discussions—were affected less frequently but still contributed to multi-service outages in some cases.
This ranking highlights how developer-facing tools (like Actions and Codespaces) tend to be more vulnerable, possibly due to their complexity and real-time dependencies.
Major Incidents and User Experience
Major incidents can be a pain, and despite its best efforts to maintain top-notch performance, GitHub isn't spared.
On August 14, 2024, a global outage made all GitHub services inaccessible for about 36 minutes, sparking immediate concern from developers worldwide. Some users reported widespread errors before GitHub officially updated its status page. The cause was a configuration change that disrupted database connectivity, and service was restored after a rollback.
Between March and May 2024, a series of smaller but recurring service disruptions affected GitHub Actions, Git operations, and Pages. While many incidents were short-lived, their frequency raised awareness among users about the ripple effects even brief downtime can have on CI/CD pipelines and collaborative development.
Outages are an inevitable part of running a global platform at scale, and GitHub has consistently worked to resolve them quickly and transparently. While some users voiced frustration, many also acknowledged the complexity of maintaining uptime across such a massive infrastructure.
These events underline the importance of visibility—especially for engineering teams that rely heavily on GitHub—to stay informed, minimize disruptions, and keep projects on track when unexpected incidents occur.
Trends in GitHub Outages: Are They Getting Worse?
Looking at GitHub's 2024 outage data, there are a few notable patterns that help us understand the platform's overall stability—and where risks might be increasing.
Outages Increased Mid-Year
GitHub saw the most outages in April (18 incidents) and July (19 incidents). These mid-year spikes may reflect periods of higher platform load or major feature rollouts. In contrast, October (4 incidents) and November (6 incidents) were relatively quiet months. The overall pattern suggests that GitHub's stability fluctuates throughout the year, with certain quarters being more volatile.
CI/CD and DevOps Tools Are Most Vulnerable
Services like GitHub Actions (25 incidents), Codespaces (14), and Git Operations (13) were among the most frequently affected components. These are mission-critical tools for DevOps workflows—so even short outages can disrupt pipelines, delay deployments, and increase developer friction.
Most Outages Are Resolved Quickly—but Some Aren't
Looking into the average resolution time for all incidents in 2024 (around 106 minutes) we noted above, GitHub is generally responsive in addressing issues. However, there were still a handful of extended outages (including one that lasted more than 19 hours), showing that severe failures still happen and can have far-reaching impacts.
Minor Disruptions Are More Common Than Major Failures
Out of 119 incidents, only 26 were major. This suggests that GitHub is relatively effective at avoiding platform-wide meltdowns—but minor disruptions can still break builds, stall code reviews, or interrupt cloud-based development sessions. These smaller incidents may not always make headlines, but they quietly slow productivity for thousands of teams.
User Strategies for Mitigating GitHub Downtime Risks
Given GitHub's role in modern development workflows, any amount of downtime can cause cascading effects across projects. While users can't control GitHub's infrastructure, they can take proactive steps to reduce risk and minimize disruption.
1. Monitor GitHub Status in Real-Time

Set up real-time status alerts using a third-party tool like IsDown to get immediate notifications when GitHub services experience issues. Monitoring specific components—such as Actions, Webhooks, or API requests—lets your team respond faster when workflows are interrupted.
2. Design CI/CD Pipelines for Resilience
Don't put all your eggs in one basket. Consider:
- Adding caching to reduce build times during recovery
- Running fallback deployment options outside GitHub
- Using self-hosted runners where appropriate
These adjustments can keep your deployment process moving even if GitHub Actions is down.
3. Enable Local Workflows and Redundancies
Encourage developers to work locally when GitHub is unstable. Using Git offline, maintaining mirror repositories, or syncing work to a secondary Git host can keep teams productive during downtime.
4. Limit Dependency on High-Risk Services
If certain services (like Codespaces or Copilot) show repeated instability, consider using them more selectively or maintaining backup environments. Balancing innovation with reliability helps avoid painful disruptions.
5. Have a Communication Plan
Even a 30-minute outage can generate confusion. Establish internal incident response channels and designate someone to relay real-time updates from GitHub or your monitoring service. This reduces panic and helps maintain momentum.
What to Expect from GitHub's Service Disruption Patterns
GitHub remains a reliable platform, but, like any cloud service, it faces operational challenges. In 2024, disruptions were common, particularly during spikes in activity or database cluster issues. Additionally, GitHub's official Incident History page reveals similar recurring challenges in 2025, including deployment issues, third-party dependencies, capacity management, and resilience.
Misconfigurations and service errors continued to affect GitHub Actions, GitHub Packages, and GitHub Copilot, reflecting patterns observed in 2024. Resource capacity issues, such as worker pool delays and database overloads in early 2025, also mirror concerns from the previous year.
While efforts are being made to address these challenges, external monitoring could further enhance the platform's resilience during peak incidents. GitHub's commitment to learning from past disruptions and improving its infrastructure is evident, but continued focus on monitoring, scaling, and testing is crucial for future stability. Implementing strong mitigation strategies and maintaining service visibility will be key to ensuring resilience, even during service disruptions.
 Nuno Tomas
Founder of IsDown
Nuno Tomas
Founder of IsDown
For IT Managers
Monitor all your dependencies in one place
One dashboard with all vendors statuses
A bird's-eye view of all your services in one place.
Get alerts when your vendors are down
Notifications in Slack, Datadog, PagerDuty, etc.
Related articles






Never again lose time looking in the wrong place
14-day free trial · No credit card required · No code required