Blog
Some updates and pieces of information.
Monitoring the Internet for you!











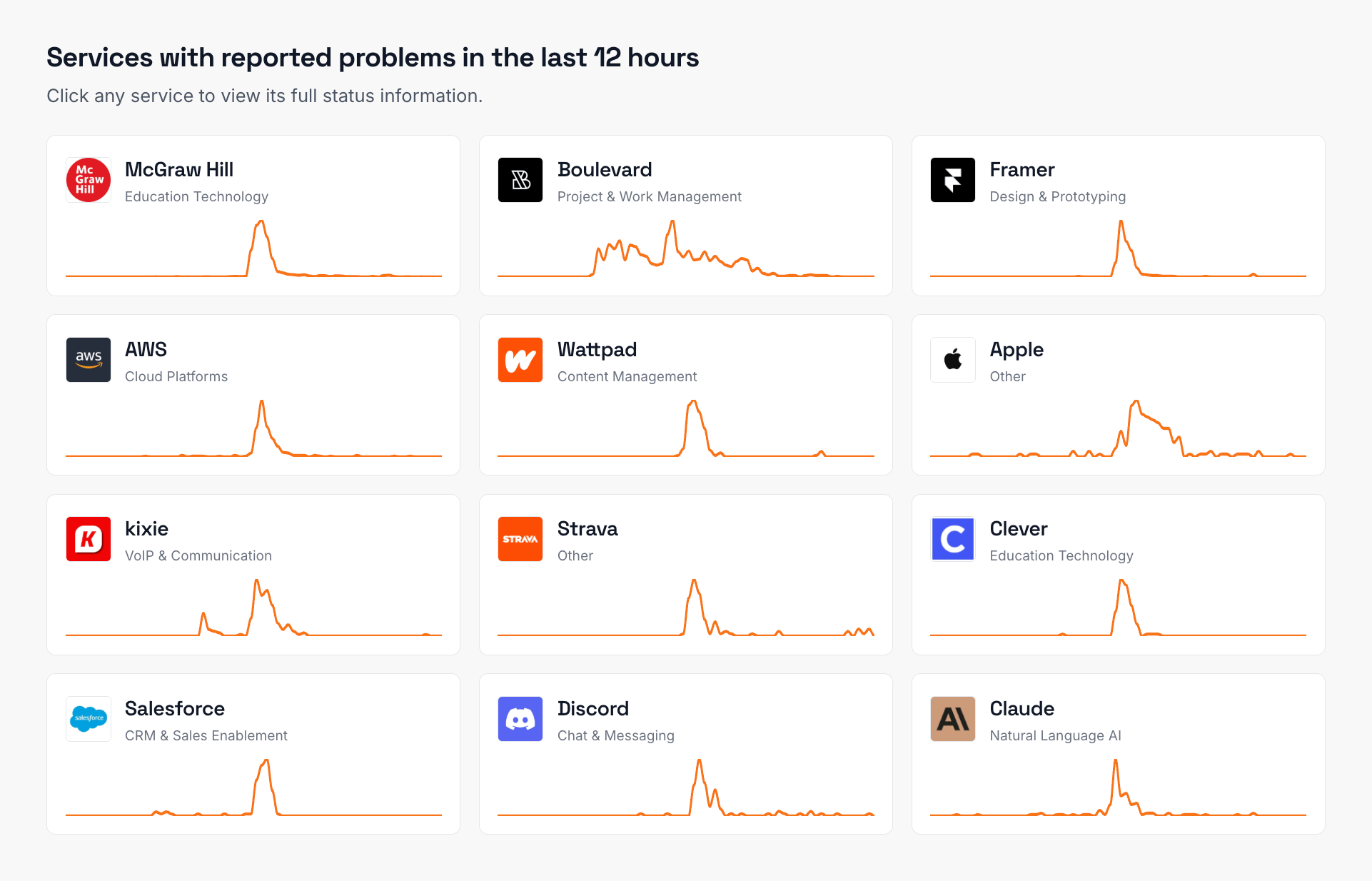


Never again lose time looking in the wrong place
14-day free trial · No credit card required · No code required
Some updates and pieces of information.
Monitoring the Internet for you!
14-day free trial · No credit card required · No code required