Cloudflare outage? The Domino Effect!

This day started a bit abruptly, with several services experiencing outages due to a Cloudflare outage.
It started approximately at 06:34 AM UTC. Check the official announcement.
A critical P0 incident was declared at approximately 06:34AM UTC. Connectivity in Cloudflare’s network has been disrupted in broad regions. Customers attempting to reach Cloudflare sites in impacted regions will observe 500 errors. The incident impacts all data plane services in our network. We will continue updating you when we have more information.
What came next was a domino effect through many popular services over the internet. Major services like Gitlab, Notion, Hubspot, Digital Ocean, Monday, Recurly, and a lot more. We registered incidents from 230 services between the outage was published until it was marked as resolved.
Here are some insights from our records, and the services we monitor.
The outage started at 6:34 AM UTC, and IsDown pick it up at 6:43 AM UTC when Cloudflare updated its status page. It got resolved approximately in around 1 hour.
We started getting reports around 4 minutes earlier (6:30 AM UTC) with the first status pages being updated.
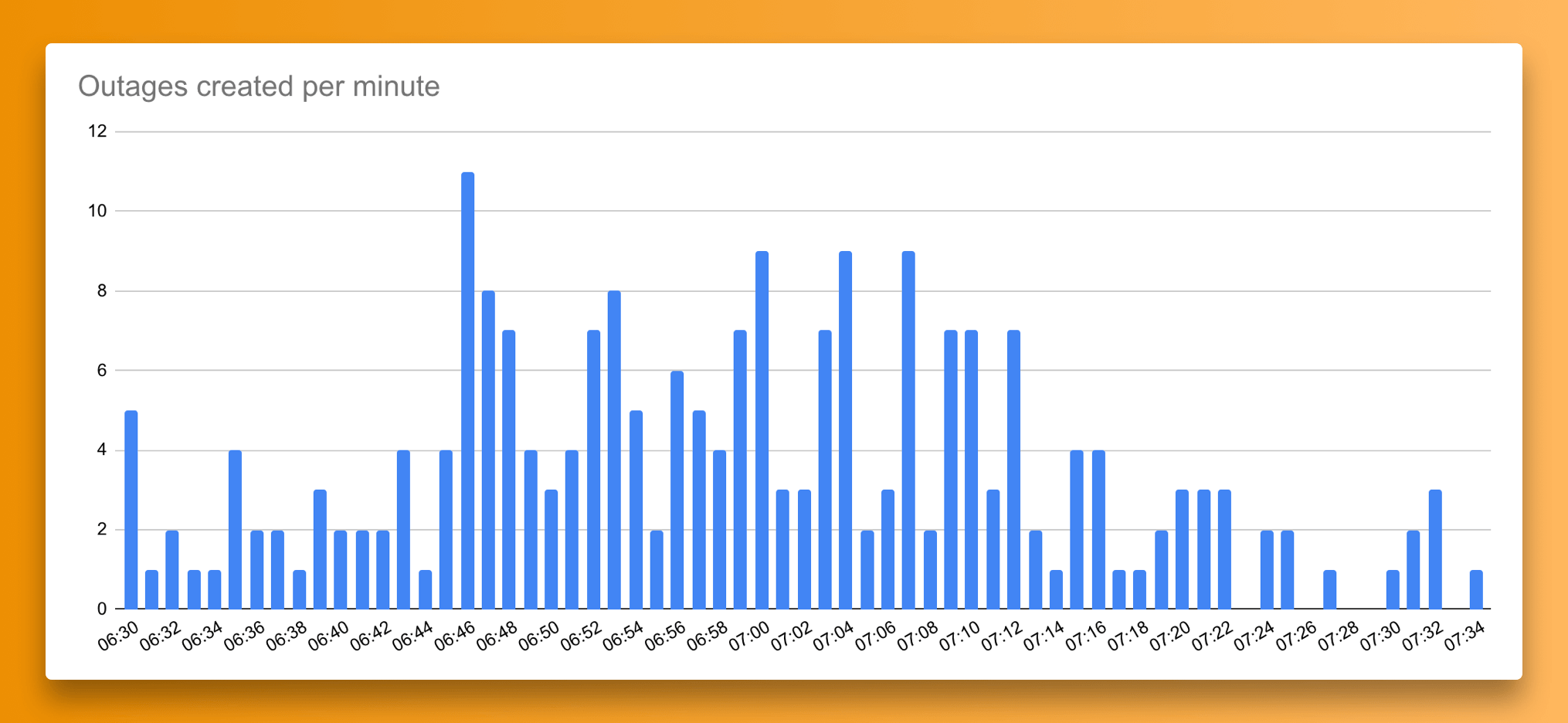
The first indication of a possible widespread issue came from companies like Magic, Pipefy, DeepSource, Descript, and The Graph, that were the first services that we monitor (according to our records) reporting an incident on their status pages.
Update: Cloudflare released a very detailed explanation of the events. It's well worth the reading.
How can IsDown help?
First, we can stop this:
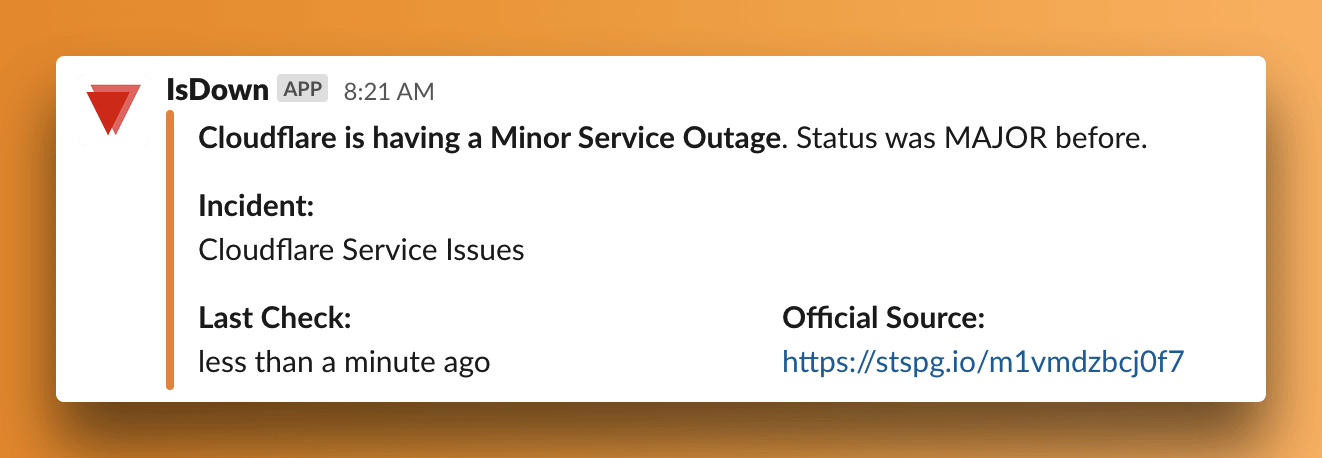
We will send you an alert to Slack or email for example. This will make your team aware, and able to refocus on the things they can control. Update the status page, inform the customers, and contact the external service.
This is the new normal! Where most of the time, it's better to buy cloud services than to build or install on-premises. Companies now have more and more external dependencies. We're talking about tens, if not hundreds of services. They make your business move faster, but it comes with the cost of depending on their availability. Most of the time, it's still a great trade-off.
That said, you still need to monitor them. And keeping an eye on all of them is hard. That's why IsDown was built. To make it simple. To have people know faster about outages and focus on the right things. This applies to most teams using cloud services, such as IT support and helpdesk teams, development teams, devops teams, and many others.
Wrapping Up
When there are outages like this, there’s little that you can do to solve it, but one thing you can do is not waste time and control the impact on your business. Having that knowledge will help you stay ahead of the curve.
 Nuno Tomas
Founder of IsDown
Nuno Tomas
Founder of IsDown
For IT Managers
Monitor all your dependencies in one place
One dashboard with all vendors statuses
A bird's-eye view of all your services in one place.
Get alerts when your vendors are down
Notifications in Slack, Datadog, PagerDuty, etc.
Related articles






Never again lose time looking in the wrong place
14-day free trial · No credit card required · No code required